REALMAN A proficient cliff detector -- from game to technology
Video
Project Summary
In the modern world, people use autonomous robots to do some work. Autonomous vacuum robots today commonly exist in many homes, it uses sensors for obstacle detection, a new feature of cliff detection has been used as an additional sensing technology for safety. Under the development of technology, we believe that auto vacuum robots should have the ability to detect cliff and down the stairs safely.
Our project is a downhill survival game in Minecraft, which asks the agent to go down the map as many valid levels (1-5 floors) as possible and maximize the reward. The agent is able to look down five floors in order to determine the next step. Once the player reaches the bottom of the map, the map will be regenerated. Rewards are given for each level the player goes down, and penalties are applied for touching the map boundary and dropping more than five levels at a time. The agent is expected to have higher rewards for optimization (considered to be a combination of less falling damages and fewer steps). Once the player reaches the bottom of the map, the map will be regenerated.
Since the agent needs to maximize the reward which is also means to minimize the damage from falling down, and the observation for the agent is limited to five floors downward. we implemented machine learning algorithms to train the agent to find the best way to reach the bottom while take minimum damage. The picture below is a illustration of one possible outcome in our map, and we wish our agent can choose the one on the left every time to maximum reward.
Fig.1: Expected agent's behavior
Approaches
Throughout the project process, we iterated a variety of algorithms and reward models, and the results obtained were also completely different.
0. DQN
The first approach we tried was using Deep Q-network(DQN) and a completely randomized map as our environment, different rewards are given when the agent getting down the hill, reaching the bottom, or touching the map boundry.
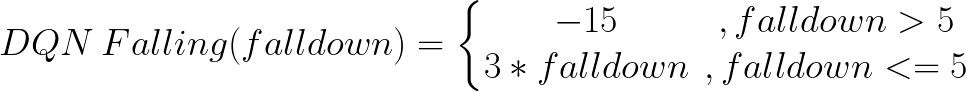
Fig. 2: Falling Rward Function
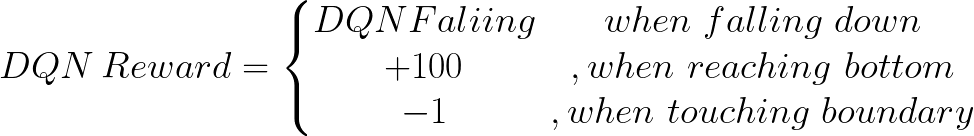
Fig.3: Rward Functions in DQN Model
DQN gives a very clear result that the agent was learning to go down the hill gradually. However, DQN runs quite unstably so we have to make the agent wait for a second or two to wait for the result to come, otherwise, the agent will choose a step randomly. It took us a lot of time experimenting with different weights for rewards, and the result was not significantly improved. With DQN as our baseline, we want the agent to do better.
After brainstorming about the situation, we decided to go with PPO(Proximal Policy Optimization) with rllib and ray to make a multi-agent environmeant. Running multiple agents parallel can significantly increase our training speed because there are more episodes being trained at the same time, and we don’t have to wait for seconds each step since PPO uses sampling to determine the weight of the following steps.
1. PPO
PPO provides a more stable result compare to the Deep Q-network but at a cost of more training steps required. Initially, we used continuous movement in our environment, but the agent will still moving when they are supposed to stop the movement for one second in some cases. So we decided to use discrete movement instead. After adjusting all kinds of parameters like “sample_batch_size”, “lr” and “evaluation_num_episodes”, we wish our learning speed can be accelerated a bit more.
trainer = ppo.PPOTrainer(env=DiamondCollector, config={
'env_config': {}, # No environment parameters to configure
'framework': 'torch', # Use pyotrch instead of tensorflow
'num_gpus': 0.03, # We aren't using GPUs now
'num_workers': 0, # We aren't using parallelism now
"train_batch_size": 500, # shrink bacth size for more learnings
"lr":0.001
})
Code. 1: Parameter tuning for PPO trainer
After discussing with our TA, we shrink our observation space from a vector that contains 4000 elements to a vector that only contains 735 elements, and we removed the reward when the agent reaching the bottom since there is no limit on steps the agent can use and it makes the agent less sensitive to the falling reward. At the meantime, we increased the reward for each level the agent manages to get down, which would stimulate the agent to jump more floors as it can.
Bugs are being fixed like miscalculating rewards while the agent is in the air by using the algorithm below. In specific, we obtained the agent position twice in a single step to calculate the difference. If the agent is falling, the position difference will be passed to our falling functin for next reward calculation.
time.sleep(0.1)
self.obs, self.temp_pos = self.get_observation(world_state)
while self.temp_pos!=self.cur_pos:
time.sleep(0.2)
self.obs, self.cur_pos = self.get_observation(world_state)
time.sleep(0.1)
self.obs, self.temp_pos = self.get_observation(world_state)
reward = 0
if self.cur_pos[1] < 3:
self.reached = True
reward += self.falling_reward(self.cur_pos, self.prev_pos)
self.prev_pos = self.cur_pos
Code. 2: Locating the agent in the air
The log frequency was adjusted a few times to show the trend of improvement, and that part is displayed in the video.
2. PPO Extension
We found that using PPO with parallelism could save us a lot of time for training because it merge contribution of each worker for each time of learning. However, due to ability of our PCs, the performance of multiple workers was worse than that of a single worker.
3. Map setup
In out first version of the game, we used 2D map as our environment for efficient implementation. However, since we want to let the agent learn a universial strategy against all kinds of map, we upgraded to a 3D map. Each stair is a 2x2 square, and we made sure each level has three stairs which allows the agent won’t encounter a situation where all possible ways lead to a negative reward. Agent are free to move in four directions.

Fig. 4: Chance of meeting cliffs
Evaluation
Quantitative Method
Evaluating the performance for our project is fairly simple, just calculate the reward the agent successfully goes down minus the damage it takes in the process. Based on the need of our model, we have adjusted the weight several times. The quantitative measure would be the final score the agent gets. In that case, rewards are given for each level the player goes down and a dynamic reward is given based on the number of levels the agent gets down. Below is our reward function and the reward is increased for each additional level it falls. Once the agent goes beyond five floors, a negative reward is given.
def falling_reward(self, cur, prev):
falldown = prev[1] - cur[1]
return -15 if falldown >= 15 else math.ceil(falldown*falldown/10)
Code. 3: Reward function
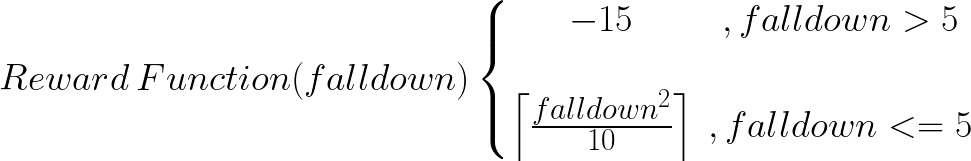
Fig. 5: Current reward function for PPO Model
Other than the penalty of dropping more than five floors, repeatedly touching the map boundary will result in a negative reward as the following XML code. Since the agent has its height, every time it touches the boundary will result in touching two glass blocks, so we change the negative reward to -1 in our reward function.
...
<Block type="glass" reward="-0.3"/>
...
...
if r.getValue() < 0:
reward += -1
...
Code. 4: Penalty of touching boundary
Qualitative Method
Another qualitative measure is that the agent is expected to have higher rewards as more training are performed, and higher reward means less falling damage and more valid floor drops. After thousands of episodes, we can see our agent stopped repeatedly touching the boundry and started to choose a path that gives higher rewards. Here is the reward graph we get that can show our agent is getting smarter as training goes on.
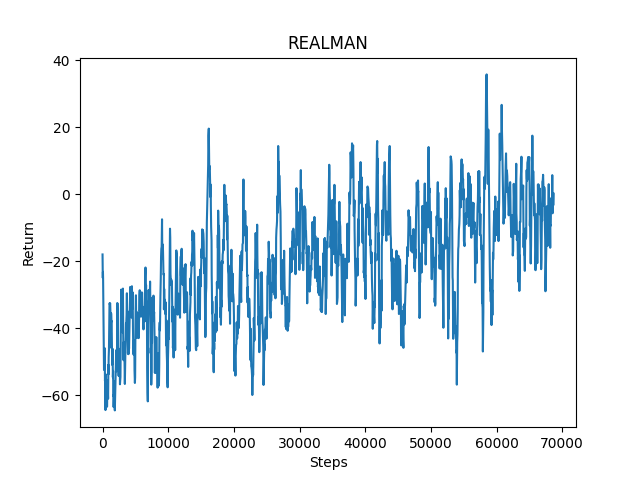
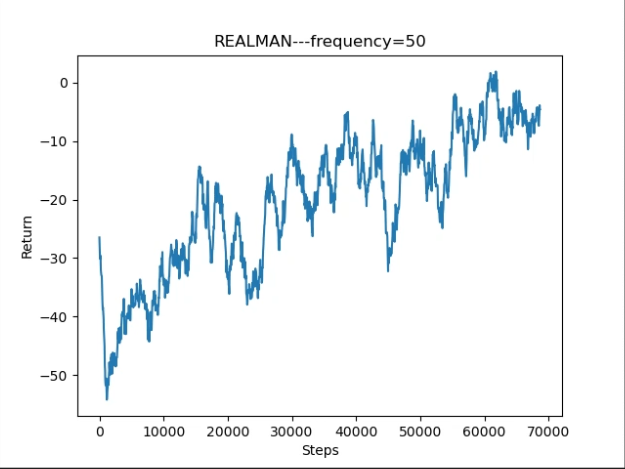
Fig. 6: Graph of qualitative result
In addition to the reward graph, we also graph the loss function as following. It shows that there are always a decreased trend when getting high loss function. We think the problem happens because of the ability of our PCs. We find that PPO needs more time for each step than DQN for better result. If there are enough learning times and enough steps, the return value will be better.
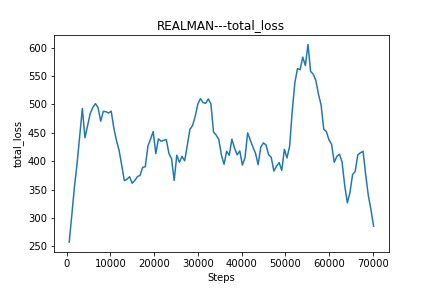
Fig. 7: Graph of loss function result